Code
library(tidyverse)
library(sf)
library(terra)
library(tidyterra)
library(gstat)
library(cowplot)Plain kriging uses the spatial structure of the response variable itself to make predictions. That works well, but it ignores something we often have access to: variables that are cheap to measure everywhere and that correlate with the thing we care about. Distance to a river, elevation, soil type, and land cover can all be derived from GIS or remote sensing data across an entire study area, even when your expensive response variable is only measured at a handful of sample points. Regression kriging (RK) combines a regression model using those covariates with kriging of the regression residuals, giving you better predictions than either approach alone.
The gstat(Pebesma and Graeler 2026) package is your friend. But we will need some of our recent collaborators as well including terra(Hijmans 2026) and tidyterra(Hernangómez 2023), plus sf(Pebesma 2026) and tidyverse(Wickham 2023) for the usual data wrangling. We’ll use cowplot(Wilke 2025) to arrange plots at the end.
library(tidyverse)
library(sf)
library(terra)
library(tidyterra)
library(gstat)
library(cowplot)The basic idea is a two-step process. First, fit an OLS regression of your response variable on whatever covariates you have available at both your sample locations and your prediction grid. Second, take the residuals from that regression, fit a variogram to them, and krige those residuals across the prediction grid. The final RK prediction at any location is the OLS fitted value plus the kriged residual:
\[\hat{Z}_{RK}(s_0) = \hat{Z}_{OLS}(s_0) + \hat{\varepsilon}(s_0)\]
The OLS surface captures the broad, covariate-driven trend: lead is higher near the river and falls off with distance. In geostatistics, this large-scale spatially varying mean is called the trend, not a trend over time but a systematic variation across space driven by covariates. The kriged residual surface captures the local spatial deviations from that trend, the pockets where lead is a bit higher or lower than the covariates alone would predict, based on what we observe at nearby sample points. Adding them together gives a prediction that is informed by both the large-scale drivers and the local spatial structure.
The residuals from the OLS model represent the spatial variation that the covariates couldn’t explain. If those residuals are spatially autocorrelated (and they often are), kriging can extract useful information from their spatial structure. In a standard OLS setting, autocorrelated residuals are a problem because they violate the independence assumption. In RK, they’re an opportunity.
RK is used more and more commonly now that cheap and powerful covariates can be derived from remote sensing and GIS data. Elevation grids, land cover maps, distance-to-feature layers: if it predicts your response and you have it everywhere, it can go in the model.
If you want a refresher on how to fit an OLS model and then apply it to new data with predict, see the Predicting New Data aside. That pattern is the foundation of the RK workflow.
Let’s look at a worked example of RK using, you guessed it, the Meuse River data. I’m pretty sick of these data but they are familiar to us. We’ve spent several chapters working with meuse2 (the point measurements) and meuse.grid2 (the prediction grid). Now we’re going to use meuse.grid2 for something beyond just holding target coordinates - we’re going to pull covariates from it directly onto our point data. That’s what makes RK possible here.
meuse2 has coordinates and metal concentrations. meuse.grid2 has terrain variables, land cover, and river distance at every grid cell. To build a regression model for lead at the sample points, we need river_dist_m at the point locations. st_join() with st_nearest_feature handles that - it matches each sample point to its nearest grid cell and pulls the column across.
meuse2 <- readRDS("data/meuse2.Rds")
meuse.grid2 <- readRDS("data/meuse.grid2.Rds")meuse2 has 164 point measurements and meuse.grid2 has 3089 grid cells. See the appendix for full variable descriptions.
We’ll model lead, the same metal we’ve been interpolating since the IDW chapter, as a function of distance to the river. As before we work with logLead, the log of the concentration, because lead is right-skewed. Distance to the river has a correlation of about -0.68 with log lead, the strongest of any variable in meuse.grid2. Other candidates (elevation, slope, TWI, soil type, flooding frequency) either don’t add much once distance is in the model or are largely redundant with it. Simple and defensible. We’ll first do this naively with OLS alone, then add the kriging step to get RK.
sf and extract covariatesMake both objects into sf, then use st_join() with st_nearest_feature to pull river_dist_m from the nearest grid cell onto each sample point.
meusePointsSf <- st_as_sf(meuse2, coords = c("x", "y"), crs = 28992)
meuseGridSf <- st_as_sf(meuse.grid2, coords = c("x", "y"), crs = 28992)
covarsSf <- meuseGridSf %>% select(river_dist_m)
meusePointsSf <- st_join(meusePointsSf, covarsSf, join = st_nearest_feature)Distance to the river is right-skewed - a handful of points are far from the channel and most are close. Log-transforming it spreads out the short-distance end of the scale where most of the variation in lead happens. We make logLead here too.
meusePointsSf <- meusePointsSf %>%
mutate(logLead = log(lead), logDist = log(river_dist_m)) %>%
drop_na(logLead)
meuseGridSf <- meuseGridSf %>%
mutate(logDist = log(river_dist_m))A simple OLS model: \(\log(\text{lead}) = \beta_0 + \beta_1 \log(\text{river\_dist}) + \varepsilon\).
leadLm <- lm(logLead ~ logDist, data = meusePointsSf)
summary(leadLm)
Call:
lm(formula = logLead ~ logDist, data = meusePointsSf)
Residuals:
Min 1Q Median 3Q Max
-1.32972 -0.33860 -0.07144 0.30170 1.51605
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 7.80779 0.25454 30.67 <2e-16 ***
logDist -0.54605 0.04523 -12.07 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.4893 on 162 degrees of freedom
Multiple R-squared: 0.4736, Adjusted R-squared: 0.4704
F-statistic: 145.8 on 1 and 162 DF, p-value: < 2.2e-16Distance to the river explains about half the variance in log lead. Now, after you learn about the pitfalls of using OLS with spatial data you’ll be appalled that I’m running this model without checking for autocorrelation in the residuals. But suppress your horror for now, because all we want to do here is show what a purely regression-based prediction surface looks like before we improve on it.
meuseGridSf$leadHat <- predict(leadLm, newdata = meuseGridSf)
# same sf2Rast function from the IDW notes, write it once, use it everywhere
sf2Rast <- function(sfObject, variable2get = 1) {
tmp <- sfObject[, variable2get] %>% st_drop_geometry()
dfObject <- data.frame(st_coordinates(sfObject), z = tmp)
rastObject <- rast(dfObject, crs = crs(sfObject))
return(rastObject)
}
meuseGridRast <- sf2Rast(meuseGridSf, variable2get = "leadHat")
ggplot() +
geom_spatraster(
data = meuseGridRast,
mapping = aes(fill = leadHat)
) +
scale_fill_terrain_c() +
labs(fill = "leadHat")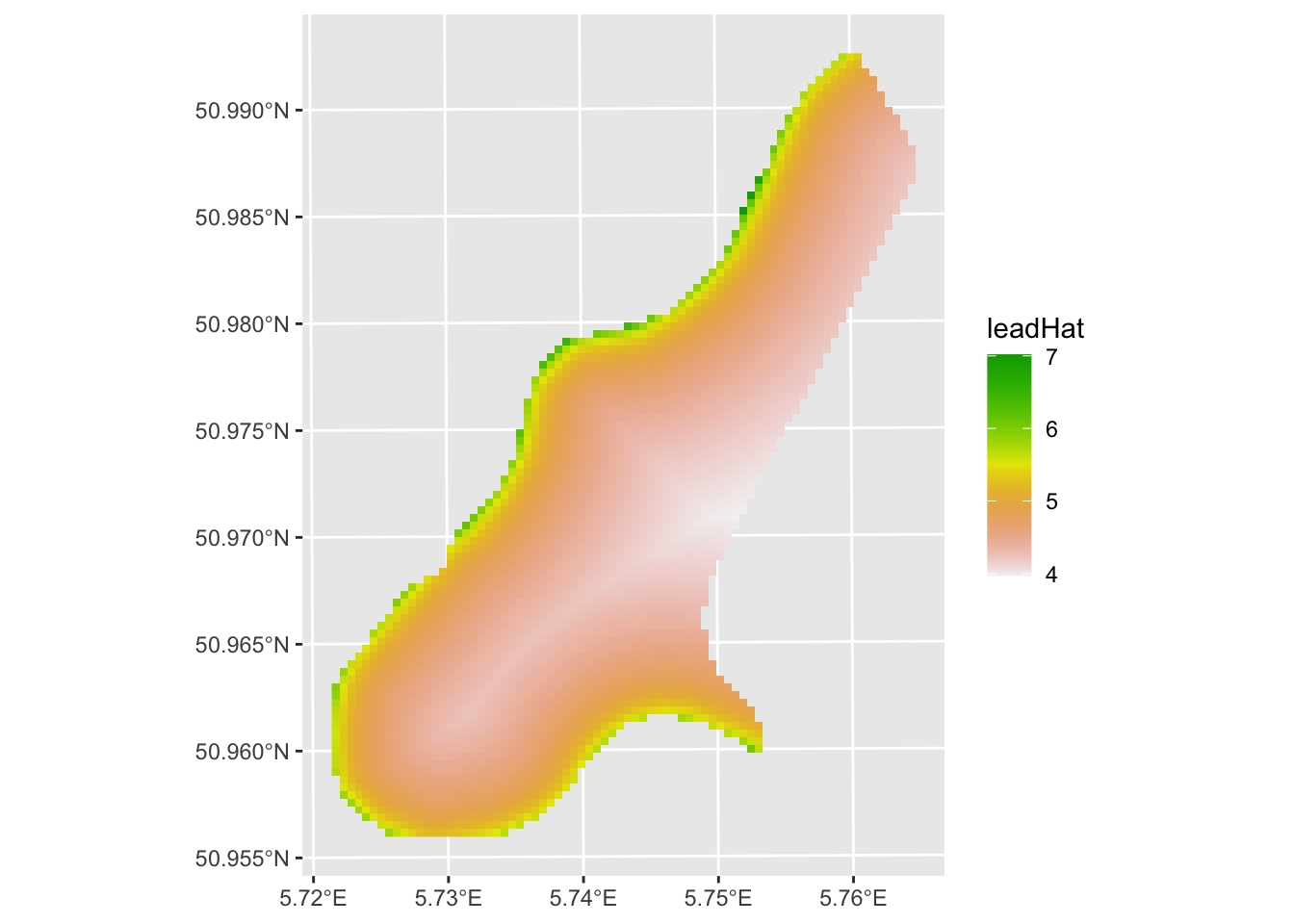
The prediction is reasonable, but the residuals are spatially autocorrelated: Moran’s I on a four-neighbor object is 0.37, significantly greater than zero. We’ll come back to that in the GLS module.
The OLS model used distance to the river but ignored everything we know about the spatial structure of lead. We threw out the variogram. And we know from the Moran’s I above that the residuals are not spatially independent, meaning there is structure left over that distance alone didn’t capture. That leftover structure is exactly what kriging is designed to exploit.
Let’s look at the variogram of logLead before conditioning on anything
leadVar <- variogram(logLead ~ 1, meusePointsSf)
plot(leadVar,
pch = 20, cex = 1.5, col = "black",
ylab = expression("Semivariance (" * gamma * ")"),
xlab = "Distance (m)", main = "Log Lead"
)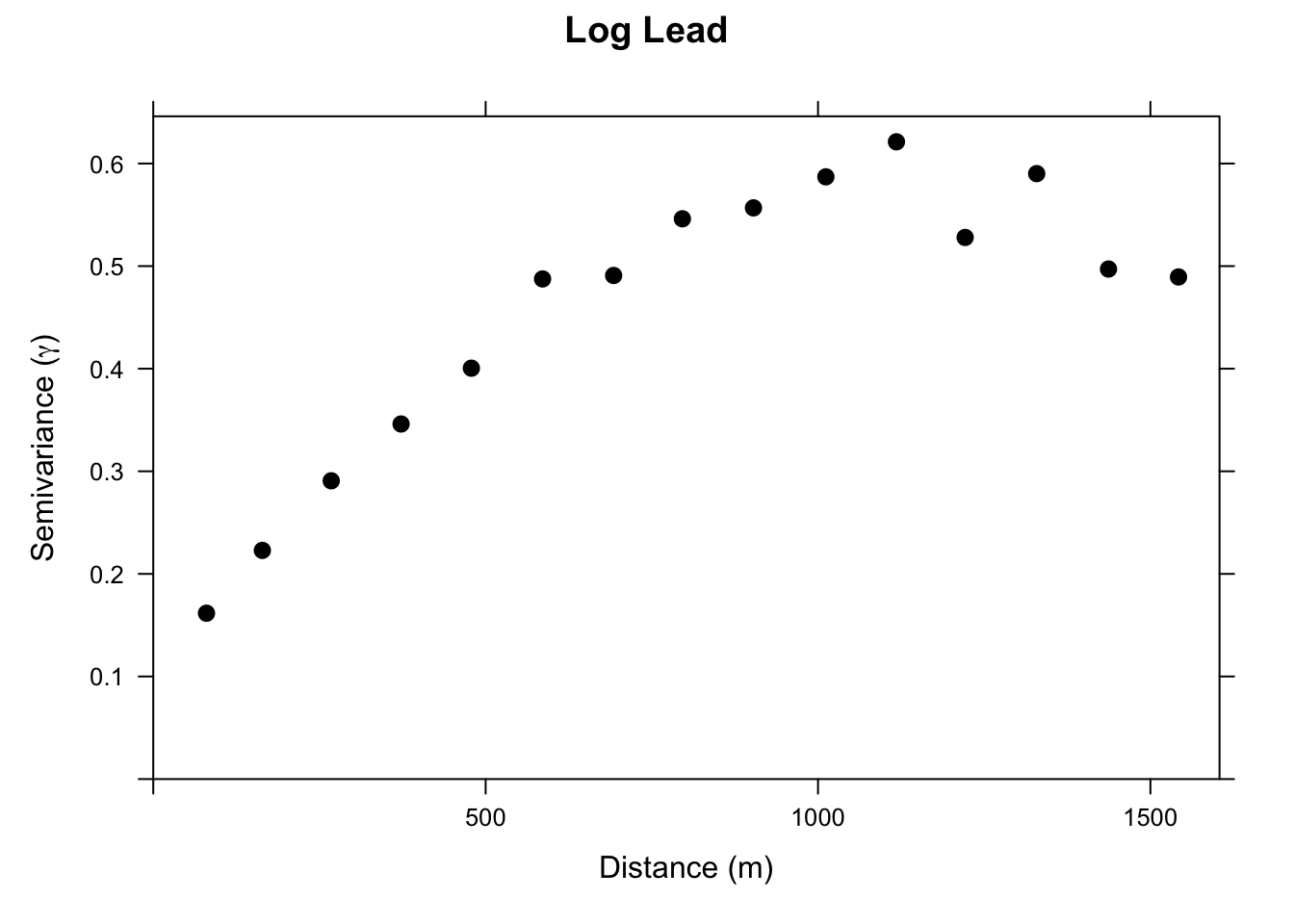
Now we set up a gstat object that includes the regression formula. When we call variogram on this object, we get the variogram of the OLS residuals, not of logLead itself. The residuals here are just the familiar \(e_i = z_i - \hat{z}_i\) at each sample point: how much higher or lower is the observed log lead than what log distance alone would predict? We’re asking whether those leftover deviations have spatial structure, or whether they’re just noise. Compare the two variogram plots and you’ll notice the residual variogram has less total variance, which is the variance the covariates explained away. What remains still has spatial structure, which means kriging has something to work with.
leadGstat <- gstat(
id = "leadModel", formula = logLead ~ logDist,
data = meusePointsSf
)
leadGstatObsVariogram <- variogram(leadGstat)
plot(leadGstatObsVariogram,
pch = 20, cex = 1.5, col = "black",
ylab = expression("Semivariance (" * gamma * ")"),
xlab = "Distance (m)", main = "Model Residuals"
)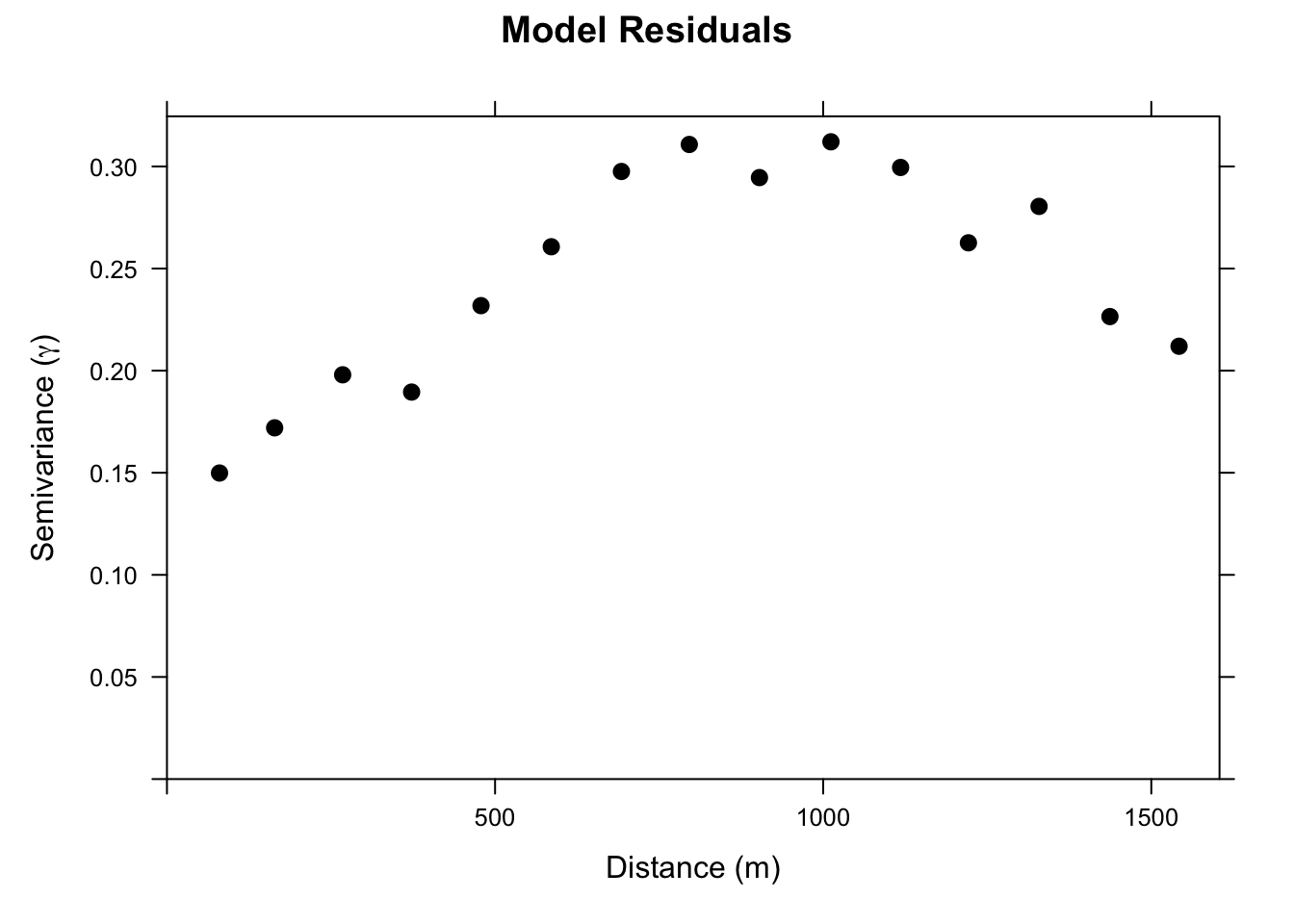
The residual variogram isn’t dramatic, but the semivariance rises from a nugget of around 0.15 to a sill of around 0.3. There is spatial structure in the residuals that we can use.
We fit a theoretical model to it. I’ll use a Gaussian model here, though an exponential would also be defensible.
leadGauVariogramModel <- vgm(psill = 0.15, model = "Gau", range = 500, nugget = 0.15)
leadGauFittedVariogram <- fit.variogram(
object = leadGstatObsVariogram,
model = leadGauVariogramModel
)
plot(leadGstatObsVariogram, leadGauFittedVariogram,
pch = 20, cex = 1.5, col = "black",
ylab = expression("Semivariance (" * gamma * ")"),
xlab = "Distance (m)", main = "Model Residuals"
)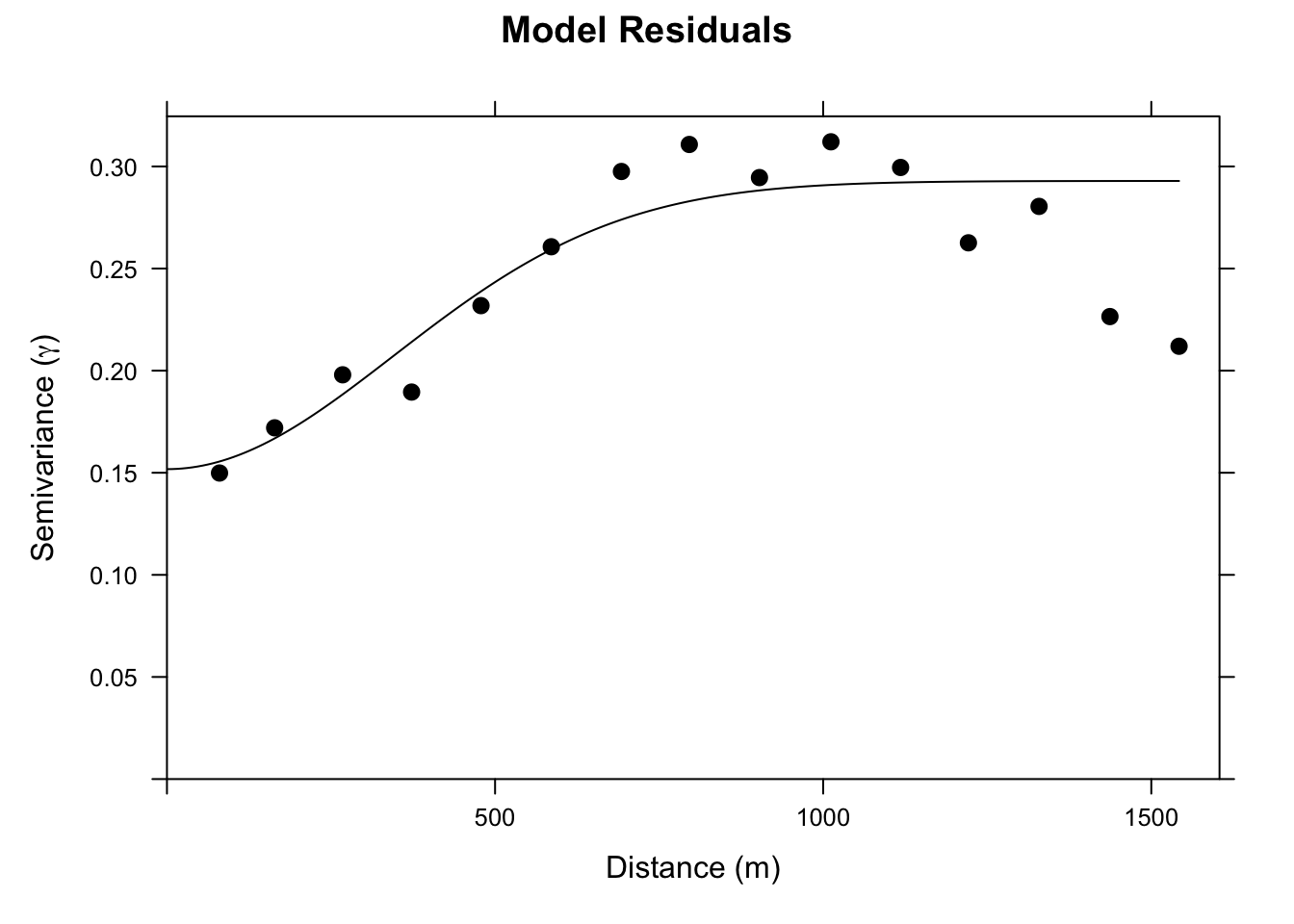
So far our gstat object holds two things: the regression formula and the data. To krige the residuals we need to give it a third, the fitted variogram model that describes their spatial structure. We add it by calling gstat() again, passing the existing object as the first argument and the fitted variogram as model. That returns a new gstat object carrying all three pieces, formula, data, and variogram, which is everything predict needs to do the regression kriging. Note that this is not R’s update method, the one we’ll use to refit a model later on. We’re just building the object up one call at a time.
Now we predict across the grid. Under the hood, predict is doing three things at every grid cell. First, it evaluates the OLS model by plugging logDist into \(\hat{\beta}_0 + \hat{\beta}_1 x_1\) to get the covariate-driven trend at that location. Second, it kriges the residuals: it looks at the OLS residuals at the nearby sample points (\(e_i = z_i - \hat{z}_i\)) and uses the fitted variogram to estimate what the residual would be at the prediction location. Third, it adds the two together. The first part handles the large-scale gradient in lead driven by distance to the river. The second part handles the local spatial deviations that distance alone couldn’t predict.
# Add the fitted variogram to the existing gstat object:
leadGstatWVariogram <- gstat(leadGstat, id = "leadModel", model = leadGauFittedVariogram)
# And predict
leadHatSf <- predict(leadGstatWVariogram, newdata = meuseGridSf)[using universal kriging]leadHatSfSimple feature collection with 3089 features and 2 fields
Geometry type: POINT
Dimension: XY
Bounding box: xmin: 178500 ymin: 329660 xmax: 181500 ymax: 333700
Projected CRS: Amersfoort / RD New
First 10 features:
leadModel.pred leadModel.var geometry
2 5.804827 0.2078498 POINT (181140 333700)
3 5.586786 0.2064161 POINT (181180 333700)
4 5.432199 0.2082940 POINT (181220 333700)
5 5.762352 0.1973711 POINT (181100 333660)
6 5.566098 0.1953315 POINT (181140 333660)
7 5.423625 0.1961995 POINT (181180 333660)
8 5.309992 0.1989750 POINT (181220 333660)
9 5.736096 0.1904506 POINT (181060 333620)
10 5.541082 0.1873068 POINT (181100 333620)
11 5.410583 0.1869815 POINT (181140 333620)To make this concrete, let’s look at all three surfaces: the OLS trend, the kriged residuals, and the final RK prediction that combines them. We have leadHat from the OLS step already. We can recover the kriged residual surface by subtracting it from the RK prediction.
leadHatRast <- sf2Rast(leadHatSf, variable2get = "leadModel.pred")
# kriged residual surface = RK prediction minus OLS trend
leadHatSf$krigedResid <- leadHatSf$leadModel.pred - meuseGridSf$leadHat
leadResidRast <- sf2Rast(leadHatSf, variable2get = "krigedResid")
pOls <- ggplot() +
geom_spatraster(data = meuseGridRast, mapping = aes(fill = leadHat)) +
scale_fill_terrain_c(limits = c(3.5, 7.5)) +
labs(title = "OLS trend", fill = "log lead") +
theme(axis.text = element_blank(), axis.ticks = element_blank())
pResid <- ggplot() +
geom_spatraster(data = leadResidRast, mapping = aes(fill = krigedResid)) +
scale_fill_gradient2(
low = "darkblue", mid = "white", high = "darkred",
midpoint = 0, na.value = "transparent"
) +
labs(title = "Kriged residuals", fill = "resid") +
theme(axis.text = element_blank(), axis.ticks = element_blank())
pRk <- ggplot() +
geom_spatraster(data = leadHatRast, mapping = aes(fill = leadModel.pred)) +
scale_fill_terrain_c(limits = c(3.5, 7.5)) +
labs(fill = "log lead") +
theme(axis.text = element_blank(), axis.ticks = element_blank())
eq <- ggdraw() + draw_label("OLS trend + Kriged residuals = RK prediction",
fontface = "italic", size = 11
)
topRow <- plot_grid(pOls, pResid, ncol = 2)
plot_grid(topRow, eq, pRk, nrow = 3, rel_heights = c(1, 0.1, 1))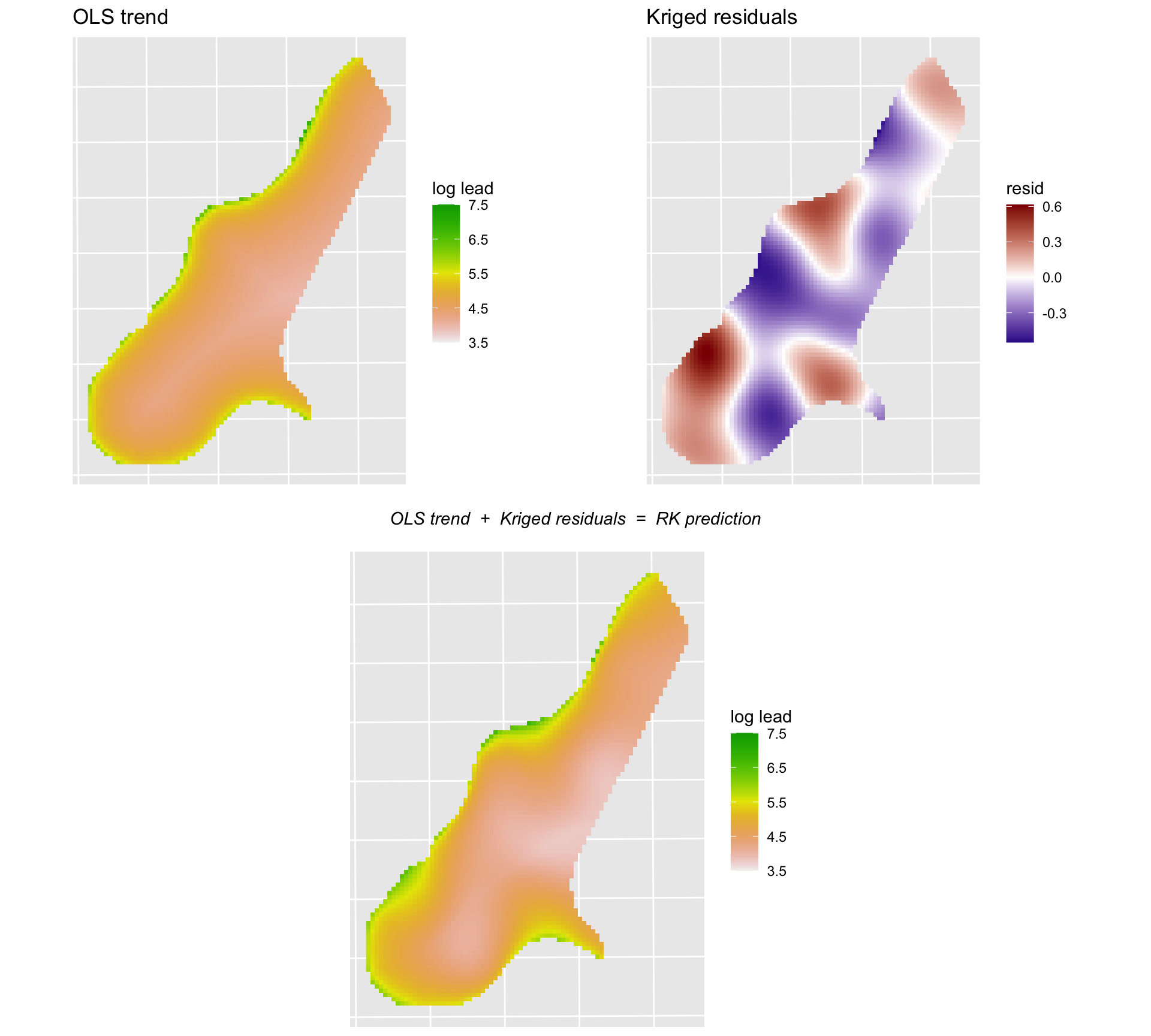
The OLS surface is smooth: it varies only with log distance to the river. The kriged residual surface shows local corrections, positive where nearby samples were higher than the OLS predicted and negative where they were lower. The RK surface is the sum, which has the broad shape of the OLS prediction but with local detail added by the kriged residuals.
And the variance surface around the RK predictions:
leadHatVarRast <- sf2Rast(leadHatSf, variable2get = "leadModel.var")
leadHatVarRast <- leadHatVarRast %>% mutate(leadModel.var.sqrt = sqrt(leadModel.var))
ggplot() +
geom_spatraster(
data = leadHatVarRast,
mapping = aes(fill = leadModel.var.sqrt)
) +
scale_fill_terrain_c() +
labs(fill = "Log Lead SD")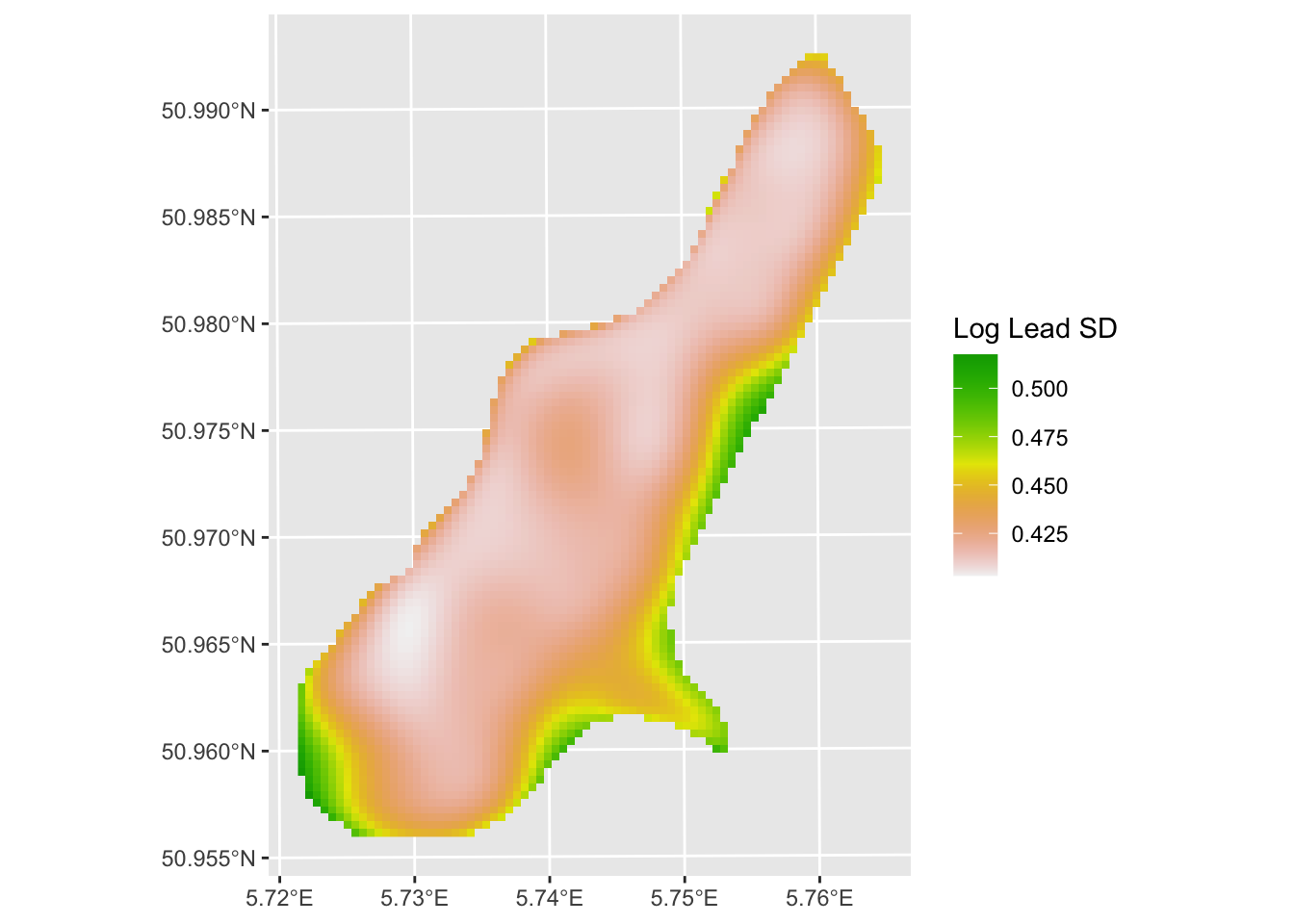
Compare the RK prediction surface to the OLS surface above. The overall gradient driven by distance to the river is still there, because that came from the regression, but the spatial detail is richer because the kriged residuals filled in structure that distance alone missed. Whether the added complexity translates to better predictive skill is a question for cross-validation.
Regression kriging combines two things you already know: a regression model that uses covariates to explain the broad spatial trend, and kriging on the residuals to capture the local structure the regression missed. The result is a prediction surface with more spatial detail than OLS alone and an uncertainty estimate that kriging brings along for free.
The method is only as good as your covariates. If distance to the river explains most of the variation in lead, RK will do well. If your regression is weak, the residual surface carries most of the weight and you’re basically back to ordinary kriging. Either way, the variance surface tells you where the predictions are most uncertain and that is information OLS will never give you.
The next two chapters take a step back. Instead of predicting a surface, we return to regression and ask what happens when OLS residuals are spatially autocorrelated. Spoiler: the coefficients are fine but the standard errors aren’t, and that matters for inference.
Use gstat.cv to cross-validate both the OLS-only model (leadGstat) and the full RK model (leadGstatWVariogram). Compute RMSE and R\(^2\) for each. Did RK improve predictions over plain OLS? How much, and where do you think the improvement (or lack of it) came from?
This was a simple model using logLead ~ logDist. What else in meuse.grid2 might be worth adding?
Meng et al. (2013) give a readable description of regression kriging and compare it to ordinary kriging and cokriging. Worth a read once you’ve worked through the examples here and want to see how the method performs in practice across different datasets.